In the previous Scrapy tutorial you learnt how to scrape information from a single page. Going further with web scraping, you will need to visit a bunch of URLs within a website and execute the same scraping script again and again. In my Jsoup tutorial and BeautifulSoup tutorial I showed you how you can paginate on a website now you will learn how to do Scrapy pagination. The CrawlSpider module makes it super easy.
Pagination with Scrapy Link to heading
As relevant example, we are going to scrape some data from Amazon. As usual, scrapy will do most of the work and now we’re using its CrawlSpider Module. It provides an attribute called rule. This is a tuple in which we define rules about links we want our crawler to follow.
First and foremost, we should setup a User Agent. The reason for this is that we want our crawler to see the site like we see it in browser and it’s fine because we don’t intend to do anything harmful. You can setup a User Agent in settings.py:
USER\_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7'
Scrapy CrawlSpider rules attribute Link to heading
So for example we’re looking for the most reviewed books in each category. In our spider file we create a Rule. This rule will define where book category links are on the page . Then callback the method we want to execute inside each category page(our starting url is amazon books page):
rules = (
Rule(LinkExtractor(restrict\_xpaths = "(//div\[@class='categoryRefinementsSection'\]/ul/li)"), callback="sort\_books"),
)
Now our crawler knows where to go. We know that amazon, like most of modern sites, uses javascript to display content. In some cases it makes scraping much more complicated but it’s a good thing that amazon works perfectly without any javascript so we don’t have to use any kind of head-less browser or such.
Scrapy FormRequest Link to heading
As I said, we need the most reviewed books in each category, let’s say the first 12 we can find on the first page. But first we should sort the books by most reviews.
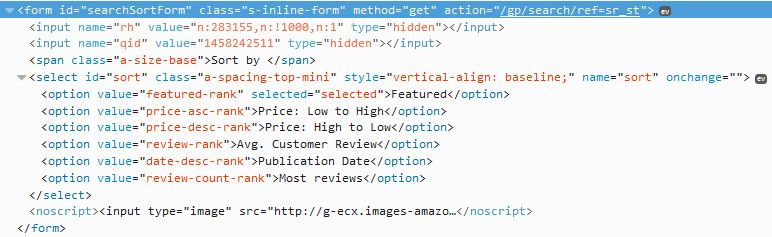
If you have a look at the source you ’ll see that we need to parse a form in order to sort. The “Go” button which will refresh the page according to the form is visible only if visiting the page without javascript enabled like our crawler does. In Scrapy we can use a FormRequest object to pass a form:
def sort_books(self, response):
sorted_form = FormRequest.from_response(
response,
formxpath="//form[@id='searchSortForm']", #xpath of form
formdata={"sort":"review-count-rank"}, #id of select node("sort") and value of "Most Reviews"("review-count-rank")
clickdata={"value":"Go"}, #the button we "click"
callback=self.parse_category #the method we execute on the sorted page
)
yield sorted_form
Data extraction Link to heading
The next and final thing we have to do is to parse each link that redirect the crawler to a book’s page where you invoke the parse_book_page method which will take care of scraping the data we’re looking for.
def parse_category(self, response):
links = response.xpath("//a[@class='a-link-normal s-access-detail-page a-text-normal']@href")
for link in links:
url = response.urljoin(link.extract())
yield Request(url, callback=self.parse_book_page)
Finally, we extract the desired details we need in parse_book_page.